What Happened Since The Last Update?
The biggest update is that I had to replace the motherboard, and run Ubuntu server 22.04 directly. Unfortunately the motherboard that I originally ordered had some sort of defect that was causing the system to not post. My first boot up with that motherboard it would hang up trying to test the memory, and after contacting the motherboard manufacturer and a few different tests it was time to order a different motherboard. The side benefit of this was that I had the opportunity to upgrade to a better motherboard with an additional 3 PCIE x16 slots. Why’s that matter? Because my goal is to be able to add more GPUs to this system, and now I will have more slots to be able to do so. Eventually I’ll migrate out of the tower case and into an open frame, or a rack mount case that I can fit more than 3 GPUs into and now I won’t have to change motherboards. A cool thing about contacting support, they actually sent me an email when the motherboard got back to them to tell me what they diagnosed. These purpose built server motherboards have remote control chips so you can remote access it and control the computer even when it’s off. The chip that did that on the board was bad, and it was preventing the system from posting.
Now what about my change from Proxmox and running VMs to running Ubuntu server 22.04? After getting the machine up and running, I installed the latest version of Proxmox and created an Ubuntu Server 22.04 VM. Unfortunately trying to pass the GPU through to the VM didn’t work quite right, and it caused a number of issues with the system. My rush to get a LLM up and running caused me to reformat the drive and install the operating system directly. Now that I have gotten to run the system for a few weeks, I have been thinking about getting back to attempting VMs and GPU passthrough in other methods than what I tried.
Time To Learn
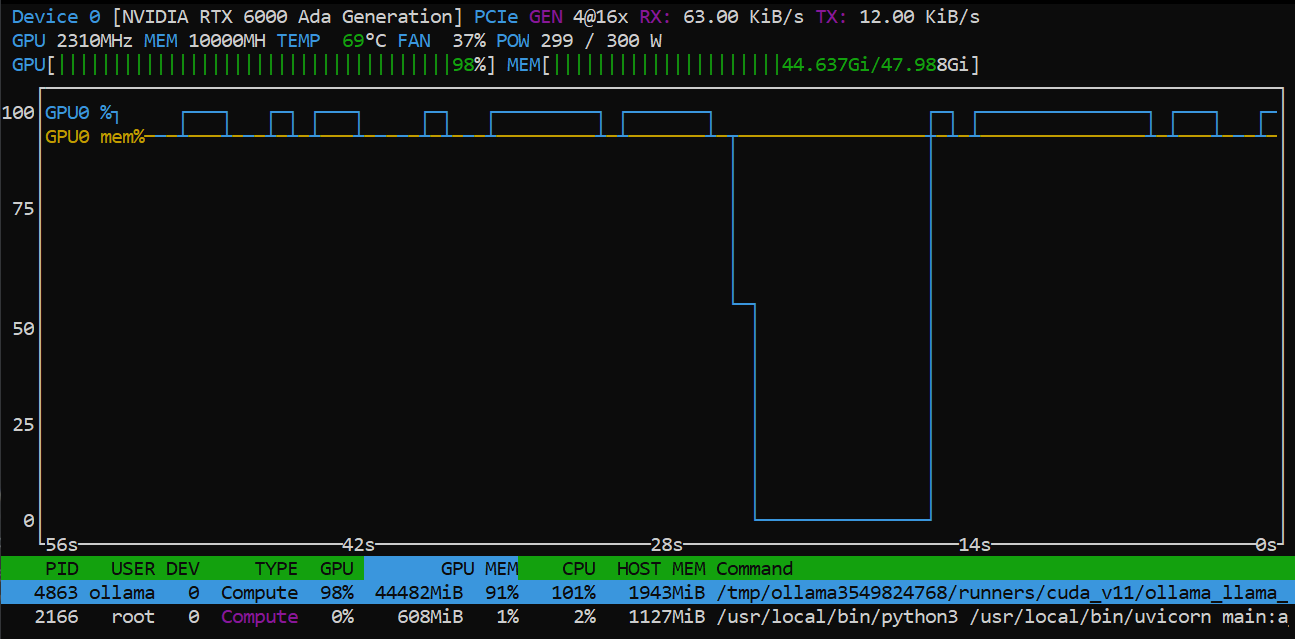
My machine was booted up, Nvidia drivers and utils were successfully installed, I got docker and other dependencies installed, and now it was time to install Ollama and run some LLM models. One of the main things I use LLMs for is to help me with coding tasks. So to evaluate models I’ll ask them to write a game of snake in python. On the Ollama site I went through and downloaded a number of models so I could start testing them out. Some models gave me code that had so many problems it wasn’t worth seeing if it could correct them. Other models gave me a perfectly working game right away, which meant I could try and iterate on that to add features to the game. I’d add high score tracking, pause and unpause, difficulty modes, and more. It was one way I could evaluate how it iterates on the code as I ask the model questions.
The primary model that I have been using has been Llama 3.1 70b-instruct-Q4_K_M. It does well with coding, and most other tasks I need it to help me with. The other convenient thing about Llama 3.1 is there is a lot of information about this model, and working with it in general. I am pairing it with Open Webui to make it like a chat GPT experience. I can download models directly from Ollama or Huggingface GGUF models and run them easily. It also is a hosted service on my machine, so I can access it easily on any local devices, or VPN into my network if I want to use my own private AI.
So What Now?
Learning finetuning and RAG is what is next on my radar. The easier one to learn so far has been RAG, and Open WebUI makes it pretty easy to do. What is RAG? Retrieval Augmented Generation, which is basically a way to increase the accuracy of the LLM with facts derived directly from documents shared with the LLM. A LLM model has been trained on a lot of very broad data, and then it is assigned weights to that data that help it generate responses based on what it is being prompted with. In general, LLMs are very good with general knowledge, but lack more specificity. If you are working on something that requires a lot of current knowledge, that can be difficult with a LLM as they typically are trained on data that is over a year old. If the LLM model you are using hasn’t been trained on the topic of the prompt, you can get what is called a halucination response. Halucinations from LLMs are when they fabricate a response that contains false information. This can be dangerous for users that have little to no knowledge on the subject they are prompting, so they trust that the responses they get from the LLM are accurate and don’t fact check.
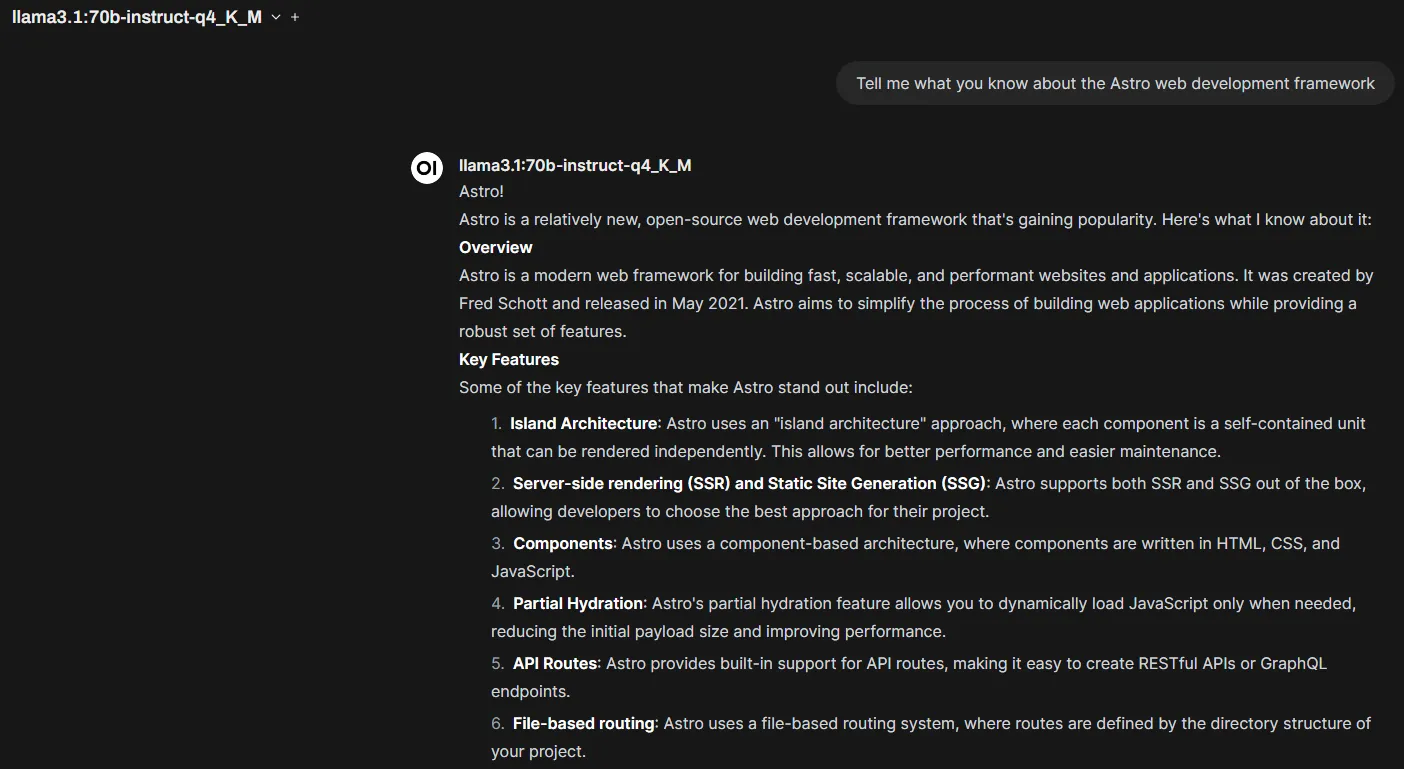
So how does RAG help with halucinations? First you provide documents with the knowledge you need the LLM to utilize in response these are the documents your LLM will ‘retrieve’ from. When prompted the LLM will try to generate the response on it’s trained knowledge, but it will consult with your documents to finalize an answer, the ‘augmented generation’ part of RAG. This helps reduce false responses, but also allows the LLM to combine it’s trained knowledge with current knowledge to generate better responses to prompts. My first efforts with RAG have been with providing the model with optimized documentation from the Astro docs website. The model has general knowledge of Astro, but because the framework is evolving quickly and is new, it doesn’t have the best current knowledge. Now when I need to ask it code questions while working within Astro it has current knowledge about the Astro framework that it can reference. When building RAG docuemntation, there are steps involved to make it easier for the LLM to read and process the information from. Everything from formatting to how long and how much overlap each document has. Between some YouTube and just prompting my LLM I have been able to come up with a python script that scrapes the information I need from webpages, formats it, and chops it into the right size pieces that I can supply to the LLM. Now you can understand why there is a lot of controvery when it comes to generative AI, they basically use copywritten information taken from the internet.
Other Updates
I haven’t made any big website changes, just some little optimizations here and there. The big things have more been on the professional front for me. My role with Plainsight as Operations Manager has me defining a lot of process and working on optimizations. Everything from simple “around the edges” type things, to optimizing core processes around product. Unfortunately I can’t get too deep into what I have accomplished so far, but I am happy to be having a lot of impact across the company. I have gotten to learn a lot really quickly about software development, platform development, security, implementation, CI/CD, and more. I get to tackle new cross functional projects week to week, and there is always something new to challenge me. I am just about to cross the 3 month mark, and I couldn’t be happier.